
-
Basic Statistics
Basic Statistics
Probability Theory
Mutually Exclusive Events and Overlapping Events
Objective and Subjective Probabilities
Conditional (Posterior) Probability
Independent Events
Law of Total Probabilities
Bayes Theorem
Discrete Probability Distribution
Binomial Distribution
Poisson Distribution
Relationship between Variables
Covariance and Correlation
Joint Probability Distribution
Sum of Random Variables
Correlation and Causation
Simpson’s Paradox
Continuous Probability Distributions
Uniform Distribution
Exponential Distribution
Normal Distribution
Standard Normal Distribution
Approximating Binomial with Normal
t-test
Hypothesis Testing
Type I and Type II Errors
Statistical Significance and Practical Significance
Hypothesis Testing Process
One-Tailed — Known Standard Deviation
Two-tailed — Known Standard Deviation
One-Tailed — Unknown Standard Deviation
Paired t-test
ANOVA
Chi-Square (χ2)
Regression
Simple Linear and Multiple Linear Regression
Least Squares Error Estimation
Overview
Sample Size
Choice of Variables
Assumptions
Normality
Linearity
Dummy Variables
Interaction Effects
Variable Selection Methods
Issues with Variables
Multicollinearity
Outliers and Influential Observations
Coefficient of Determination (R2)
Adjusted R2
F-ratio: Overall Model
t-test: Coefficients
Goodness-of-fit
Validation
Process
Factor Analysis
- Basic Statistics
- Sampling
- Marketing mix Modelling
Coronavirus — What the metrics do not reveal?
Coronavirus — Determining death rate
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
-
MarketingMind
Basic Statistics
Basic Statistics
Probability Theory
Mutually Exclusive Events and Overlapping Events
Objective and Subjective Probabilities
Conditional (Posterior) Probability
Independent Events
Law of Total Probabilities
Bayes Theorem
Discrete Probability Distribution
Binomial Distribution
Poisson Distribution
Relationship between Variables
Covariance and Correlation
Joint Probability Distribution
Sum of Random Variables
Correlation and Causation
Simpson’s Paradox
Continuous Probability Distributions
Uniform Distribution
Exponential Distribution
Normal Distribution
Standard Normal Distribution
Approximating Binomial with Normal
t-test
Hypothesis Testing
Type I and Type II Errors
Statistical Significance and Practical Significance
Hypothesis Testing Process
One-Tailed — Known Standard Deviation
Two-tailed — Known Standard Deviation
One-Tailed — Unknown Standard Deviation
Paired t-test
ANOVA
Chi-Square (χ2)
Regression
Simple Linear and Multiple Linear Regression
Least Squares Error Estimation
Overview
Sample Size
Choice of Variables
Assumptions
Normality
Linearity
Dummy Variables
Interaction Effects
Variable Selection Methods
Issues with Variables
Multicollinearity
Outliers and Influential Observations
Coefficient of Determination (R2)
Adjusted R2
F-ratio: Overall Model
t-test: Coefficients
Goodness-of-fit
Validation
Process
Factor Analysis
- Basic Statistics
- Sampling
- Marketing mix Modelling
Coronavirus — What the metrics do not reveal?
Coronavirus — Determining death rate
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
Chi-Square (χ2) test of Independence
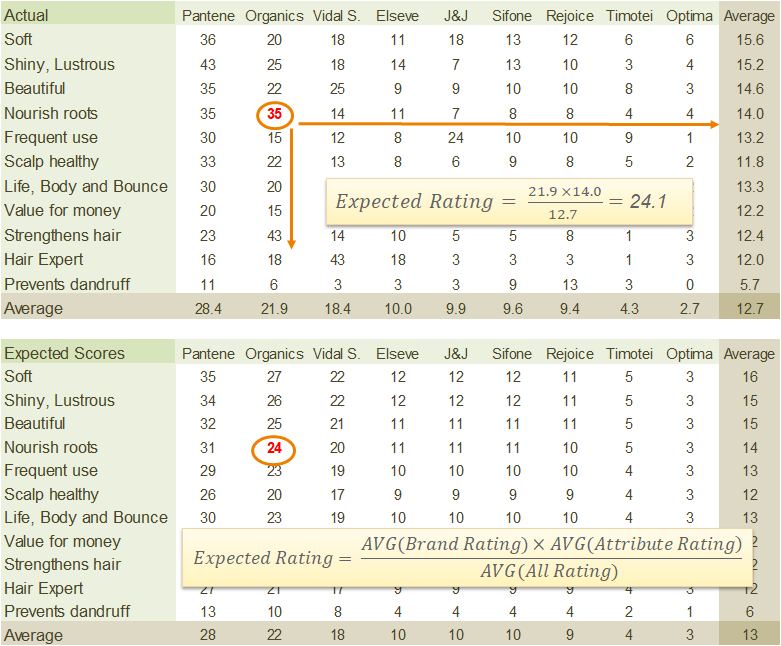
Exhibit 34.24 Computation of expected score (Example — shampoo data, from Exhibit 1.8, Chapter Brand Sensing).
The chi-squared test is used to determine whether there is a significant difference between the expected frequencies and the observed frequencies in one or more categories.
Take for instance the data on the image rating (top2box score) of shampoo brands in Exhibit 34.24. To gauge the image profile of Organics shampoo, the brand manager needs to compare attribute ratings for the brand with competing brands.
You may recall from Chapter Brand Sensing that the basis for comparison is the Expected Score: $$Expected Score=\frac{AVG(Brand Score)×AVG(Attribute Score)}{AVG(All Score)}$$ $$ = \frac{AVG(Column)×AVG(Row)}{AVG(All)}$$
Note: Total scores may be used, instead of average score.
The attribute profile (Profile = Actual Score – Expected Score) reveals whether the brand’s association with the attribute is strong (profile > 0) or weak (profile < 0). Organics shampoo for instance is strongly associated with the attribute ‘Nourishes Roots’ (Profile = 35 – 24 = 11).
While big brands like Pantene and Organics are rated high on all attributes, image profiling mathematically eliminates influence of brand and attribute “size” to determine each brand’s strengths and weaknesses in relation to each other, expressed as variation from what one would expect if the brand were average.
Chi-Square (χ2) test of independence is a universal metric that standardizes the data so that it becomes comparable across data sets of different magnitude.
$$Chi˗square \,statistic:\,χ^2 = \sum\frac{(Observed-Expected)^2}{Expected}=\sum\frac{Profile^2}{Expected}$$For Organics on the attribute nourishes roots:
$$Chi˗square \,value \,of \,the \,cell=\frac{(Observed-Expected)^2}{Expected}=\frac{(35-24)^2}{24}=4.9$$For the entire data set, sum of these quantities over all the cells is the Chi˗square test statistic:
$$Chi˗square\, statistic \,χ2 = \sum\frac{(Observed-Expected)^2}{Expected}=230.4$$This has approximately a chi-squared distribution whose number of degrees of freedom are: $$df =degrees \,of \,freedom=(attributes-1)(brands-1)=(11 - 1)(9 -1)=80$$
Under the null hypothesis there is no difference in the proportions across brands. If the test statistic for the chi-squared distribution is improbably large, then the null hypothesis is rejected.
In our shampoo example, since the p-value (for χ2 = 230.4, df = 80) is extremely small (less than .00001), i.e., p-value << 0.05, the null hypothesis is rejected. There are significant differences in the attribute ratings across the brands.
The Chi-square test is often used in research studies to test the relationship between a variable pertaining to behaviour or attitude, with a variable pertaining to classification. For instance, the relationship between the consumption of a product with income level, location, or age. The variables are cross tabulated, and then tested. The test will reveal whether relationship exists between the two variables.
Note: Chi-square function in Excel is CHISQ.TEST. In SPSS the analysis falls under ‘Descriptive statistics’ > ‘Crosstab’. Check the Chi-square box within the statistics pop-up page.
Previous Next
Use the Search Bar to find content on MarketingMind.





Contact | Privacy Statement | Disclaimer: Opinions and views expressed on www.ashokcharan.com are the author’s personal views, and do not represent the official views of the National University of Singapore (NUS) or the NUS Business School | © Copyright 2013-2026 www.ashokcharan.com. All Rights Reserved.