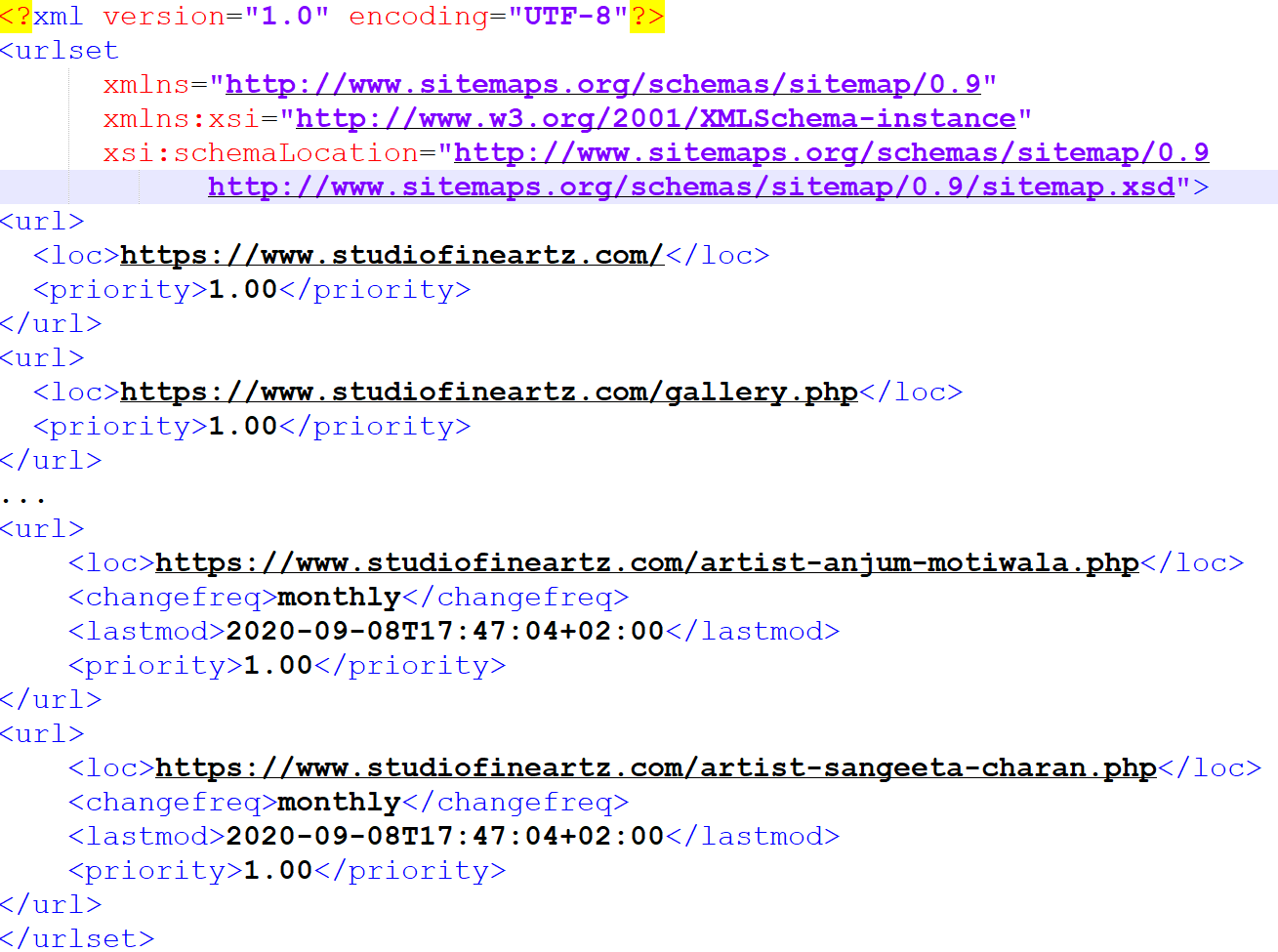
Exhibit 26.18 Sitemap for studiofineartz.com.
Sitemaps maintain a list of the website’s pages for crawlers to effortlessly crawl
the entire site. They are formatted as XLM files (Exhibit 26.18) that crawlers are designed to read and follow.
Irrespective of the presence of sitemaps, crawlers do comb pages to seek and follow internal links, moving page to page until the
entire site is crawled. While they are not necessarily required, search algorithms do favourably
rank sites that maintain sitemaps.
According to Google, sitemaps are particularly helpful if:
- The site has content that is dynamically rendered, i.e., pages are dynamically created by passing
variables to the server. (Examples: view.php?id=123, https://www.studiofineartz.com/artist.php?name=Sangeeta%20Charan).
- The site has pages that are not easily found by robots during the
crawl process — for example, pages featuring rich AJAX or Flash.
- The site is new and relatively isolated. (Spiders like Googlebot crawl the web by following
links from one page to another, so if a site is not well linked, browsers may find it hard to find).
- The site has a large archive of content pages that are not well linked to
each other or are not linked at all.
Exhibit 26.19 XML-Sitemaps.com — freeware for generating sitemaps.
Freeware like
XML-Sitemaps shown in Exhibit
26.19, make it is easy to generate sitemaps.
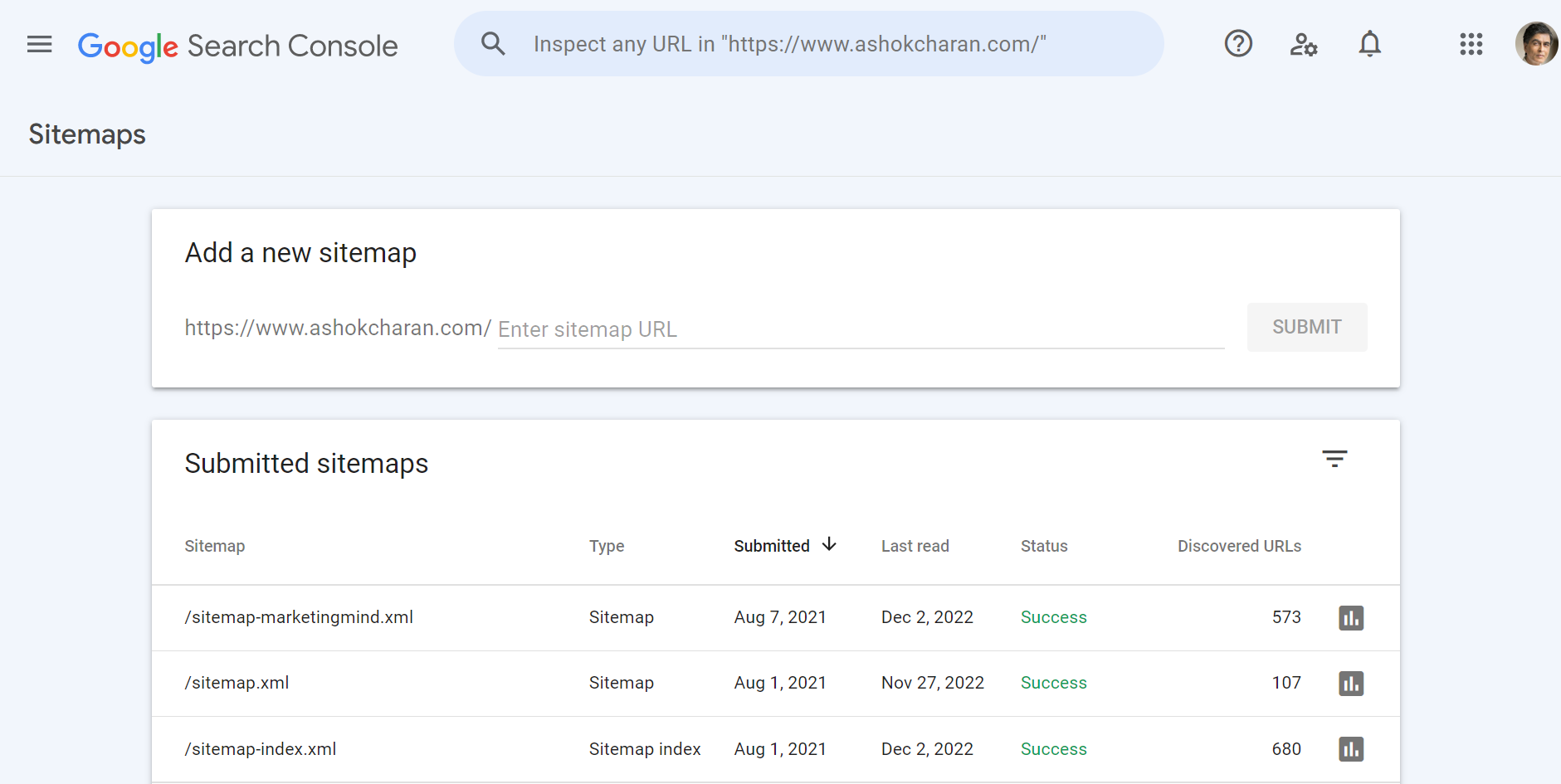
Exhibit 26.20 Submission of sitemap via Google’s Search Console.
Sitemaps are be submitted to Google via Google’s Search Console
(see Exhibit 26.20).
In addition to sitemaps, search engine crawlers also look for the robots.txt
file on websites. The robots.txt file is a text file that is located in the root directory of a
website and contains instructions for search engine crawlers. It can be used to restrict search
engines from crawling or indexing restricted pages or directories on a website. This can be useful
for pages or directories that contain sensitive information or are not intended to be publicly
available.





