
-
Social Media Analytics
Social Media Analytics
Why Social Media Matters for Brands
Insights Gleaned from Social Media Platforms
Strengths of Social Media Data
Limitations of Social Media Data
Understanding Social Data
Social Media Platforms: Key Features
Structured and Unstructured-Data
Social Data Mining
Social Data Mining Process
Social Data Mining Techniques
Social Data Mining Challenges
Application Programming Interfaces
How APIs Work
Working with APIs
Endpoints
Twitter (X) API
Twitter (X) API — Securing Access
Twitter (X) REST API in Python
Facebook API
Facebook Graph API
Facebook API — Securing Access
Facebook API in Python
Advantages and Limitations of APIs
Data Cleaning Techniques
Natural Language Processing
Natural Language Toolkit (NLTK)
Social Media Data Types
Textual Data Encoding
Text Processing Techniques
Tokenization
Word Tokenization
Character Tokenization
Sub-Word Tokenization
Stemming and Lemmatization
Stemming
Lemmatization
Stemming and Lemmatization in Python
N-grams, Bigrams, and Trigrams
Applications of N-grams
Applications of N-grams in Sentiment Analysis
Topic Modelling with N-grams
Vectorization
Bag-of-Words
TF-IDF Vectorizer
Facebook Brand Page Analysis
Extracting Insights from Facebook Brand Pages
Facebook — Social Data Analysis Process
Facebook — Data Extraction
Text Analytics
Text Analytics Process
Part of Speech (POS) Tagging
Noun Phrases
Text Data Processing in Python
Word Cloud (FB data) in Python
Time Series Analysis and Visualization of FB Comments
Emotion Analysis
IBM Watson Natural Language Understanding
Accessing IBM Cloud Services
Emotion Analysis Using Watson NLU
Sentiment Analysis
Forms of Sentiment Analysis
Types of Sentiment Analysis
Visual Sentiment Analysis and Facial Coding
Applications of Facial Coding
Sentiment Analysis in Text
Analysis of Behaviours and Sentiments
Sentiment Analysis Process
Sentiment Analysis — Classification
VADER Classifier
Standard Sentiment Analysis
Customised Sentiment Analysis
Model Validation – Confusion Matrix
K-fold Cross-validation
Named Entity Recognition (NER)
NER Process Overview
Stanford NER
Challenges in NER
Stanford NER Implementation in Python
Web Scraping
Web Scraping Techniques
Applications of Web Scraping
Legal and Ethical Considerations
Beautiful Soup
Scraping Quotes to Scrape
Scraping of Fake Jobs Webpage
Scrapy
Scrapy Concepts
Scrapy Framework
Scrapy Limitations
Beautiful Soup vs. Scrapy — A Comparison
Selenium
Topic Modelling
Topic Modelling — Illustration
Topic Modelling Techniques
Topic Modelling Process
Latent Dirichlet Allocation (LDA) Model
Topic Modelling Tweets with LDA in Python
Social Influence on Social Media
Key Forms of Social Influence
Social Influence on Social Media Platforms
Examples of Organized Social Influence
Social Network Analysis
Topic Networks and User Networks
Online Social Networks — The Basics
Analysing Topic Networks
Centrality Measures
Degree Centrality
Betweenness Centrality
Closeness Centrality
Eigenvector Centrality
Use Case — Marketing Analytics Topic Network
Social Network Analysis Process
SNA — Uncovering User Communities
Appendix — Python Basics: Tutorial
Installation — Anaconda, Jupyter and Python
Python Syntax
Variables
Data Types
If Else Statement
While and For Loops
Functions (def)
Lambda Functions
Modules
JSON
Python Requests — get(), json()
User Input
Exercises
Appendix — Python Pandas
Basic Usage
Reading, Writing and Viewing Data
Data Cleaning
Other Features
Appendix — Python Visualization
Matplotlib
Matplotlib — Basic Plotting
NumPy
Matplotlib — Beyond Lines
Analysis and Visualization of the Iris Dataset
Word Clouds
Word Cloud in Python
Seaborn — Statistical Data Visualization
Seaborn Visualization in Python
Appendix — Scrapy Tutorial
Creating a Project
Writing a Spider
Running the Spider
Extracting Data
Extracting Data — CSS Method
Extracting Data — XPath Method
Extracting Quotes and Authors
Extracting Data in Spider
Storing the Scraped Data
Pipeline
Following Links
Appendix — HTML Basics
HTML Tree Structure, Tags and Attributes
Tags
Attributes
My First Webpage
- New Media
- Digital Marketing
- YouTube
- Social Media Analytics
- SEO
- Search Advertising
- Web Analytics
- Execution
- Case — Prop-GPT
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
-
MarketingMind
Social Media Analytics
Social Media Analytics
Why Social Media Matters for Brands
Insights Gleaned from Social Media Platforms
Strengths of Social Media Data
Limitations of Social Media Data
Understanding Social Data
Social Media Platforms: Key Features
Structured and Unstructured-Data
Social Data Mining
Social Data Mining Process
Social Data Mining Techniques
Social Data Mining Challenges
Application Programming Interfaces
How APIs Work
Working with APIs
Endpoints
Twitter (X) API
Twitter (X) API — Securing Access
Twitter (X) REST API in Python
Facebook API
Facebook Graph API
Facebook API — Securing Access
Facebook API in Python
Advantages and Limitations of APIs
Data Cleaning Techniques
Natural Language Processing
Natural Language Toolkit (NLTK)
Social Media Data Types
Textual Data Encoding
Text Processing Techniques
Tokenization
Word Tokenization
Character Tokenization
Sub-Word Tokenization
Stemming and Lemmatization
Stemming
Lemmatization
Stemming and Lemmatization in Python
N-grams, Bigrams, and Trigrams
Applications of N-grams
Applications of N-grams in Sentiment Analysis
Topic Modelling with N-grams
Vectorization
Bag-of-Words
TF-IDF Vectorizer
Facebook Brand Page Analysis
Extracting Insights from Facebook Brand Pages
Facebook — Social Data Analysis Process
Facebook — Data Extraction
Text Analytics
Text Analytics Process
Part of Speech (POS) Tagging
Noun Phrases
Text Data Processing in Python
Word Cloud (FB data) in Python
Time Series Analysis and Visualization of FB Comments
Emotion Analysis
IBM Watson Natural Language Understanding
Accessing IBM Cloud Services
Emotion Analysis Using Watson NLU
Sentiment Analysis
Forms of Sentiment Analysis
Types of Sentiment Analysis
Visual Sentiment Analysis and Facial Coding
Applications of Facial Coding
Sentiment Analysis in Text
Analysis of Behaviours and Sentiments
Sentiment Analysis Process
Sentiment Analysis — Classification
VADER Classifier
Standard Sentiment Analysis
Customised Sentiment Analysis
Model Validation – Confusion Matrix
K-fold Cross-validation
Named Entity Recognition (NER)
NER Process Overview
Stanford NER
Challenges in NER
Stanford NER Implementation in Python
Web Scraping
Web Scraping Techniques
Applications of Web Scraping
Legal and Ethical Considerations
Beautiful Soup
Scraping Quotes to Scrape
Scraping of Fake Jobs Webpage
Scrapy
Scrapy Concepts
Scrapy Framework
Scrapy Limitations
Beautiful Soup vs. Scrapy — A Comparison
Selenium
Topic Modelling
Topic Modelling — Illustration
Topic Modelling Techniques
Topic Modelling Process
Latent Dirichlet Allocation (LDA) Model
Topic Modelling Tweets with LDA in Python
Social Influence on Social Media
Key Forms of Social Influence
Social Influence on Social Media Platforms
Examples of Organized Social Influence
Social Network Analysis
Topic Networks and User Networks
Online Social Networks — The Basics
Analysing Topic Networks
Centrality Measures
Degree Centrality
Betweenness Centrality
Closeness Centrality
Eigenvector Centrality
Use Case — Marketing Analytics Topic Network
Social Network Analysis Process
SNA — Uncovering User Communities
Appendix — Python Basics: Tutorial
Installation — Anaconda, Jupyter and Python
Python Syntax
Variables
Data Types
If Else Statement
While and For Loops
Functions (def)
Lambda Functions
Modules
JSON
Python Requests — get(), json()
User Input
Exercises
Appendix — Python Pandas
Basic Usage
Reading, Writing and Viewing Data
Data Cleaning
Other Features
Appendix — Python Visualization
Matplotlib
Matplotlib — Basic Plotting
NumPy
Matplotlib — Beyond Lines
Analysis and Visualization of the Iris Dataset
Word Clouds
Word Cloud in Python
Seaborn — Statistical Data Visualization
Seaborn Visualization in Python
Appendix — Scrapy Tutorial
Creating a Project
Writing a Spider
Running the Spider
Extracting Data
Extracting Data — CSS Method
Extracting Data — XPath Method
Extracting Quotes and Authors
Extracting Data in Spider
Storing the Scraped Data
Pipeline
Following Links
Appendix — HTML Basics
HTML Tree Structure, Tags and Attributes
Tags
Attributes
My First Webpage
- New Media
- Digital Marketing
- YouTube
- Social Media Analytics
- SEO
- Search Advertising
- Web Analytics
- Execution
- Case — Prop-GPT
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
Stanford NER Implementation in Python
Exhibit 25.31 demonstrates the Python implementation of Named Entity Recognition (NER) using Stanford NER to identify and classify entities into three categories — organization, person, location. The entites are sourced from tweets associated with the English Premier League.
The process involves the following steps:
- Download and Setup: Download Stanford NER and move the classifier file to your desired directory. Initialize the StanfordNERTagger and assign it to the variable st, specifying the directory where the classifier file is located. Use english.all.3class.distsim (a three-class classifier) to identify the three categories of named entities.
- Read Data: Read the tweets from the file
tweets-statuses.json. - Tag Named Entities: Iterate through the list of tweets and:
- Tag the named entities.
- Extract and store only entities related to the three categories: organizations, persons, and locations. Entities that are tagged ‘O’ are excluded. (The ‘O’ tag in the Stanford NER Tagger stands for “Outside”. It is used to mark words that do not belong to any named entity class in the Named Entity Recognition process).
- Store and Filter Data: Load the entity tuples into a DataFrame df_entities and name the columns “word” and “ner”.
- Extract Organizations: Filter df_entities to extract rows where NER equals “Organizations”. Get the top 10 organizations.
- Extract Persons and Locations: Repeat the previous step to extract persons and locations.
- Search Specific Entities: Extract the tweets containing the organization ‘Liverpool’.
Note the ambiguity arrising from words such as Manchester and Madrid which fall under multiple categories — location (Manchester, Madrid) and organization (Manchester United, Real Madrid). Manual cleaning is required in such cases to ensure that entities are correctly tagged.
Import and Setup
import os
java_path = "C:/Program Files/Java/jdk-16.0.1/bin/java.exe"
os.environ['JAVAHOME'] = java_path
import urllib.request
import zipfile
from nltk.tag.stanford import StanfordNERTagger
# Set the direct path to the NER Tagger.
# Use english.all.3class.distsim (three class classifier) to find three classes of named entities.
_model_filename = r'C:\Delphi\Web\Marketing-Analytics\py\data\stanford-ner-2015-04-20\classifiers\english.all.3class.distsim.crf.ser.gz'
_path_to_jar = r'C:\Delphi\Web\Marketing-Analytics\py\data\stanford-ner-2015-04-20\stanford-ner.jar'
# Initialize the NLTK's Stanford NER Tagger API with the DIRECT PATH to the model and .jar file.
st = StanfordNERTagger(model_filename=_model_filename, path_to_jar=_path_to_jar)
entities = []
Read Data
# read the tweets
import pandas as pd
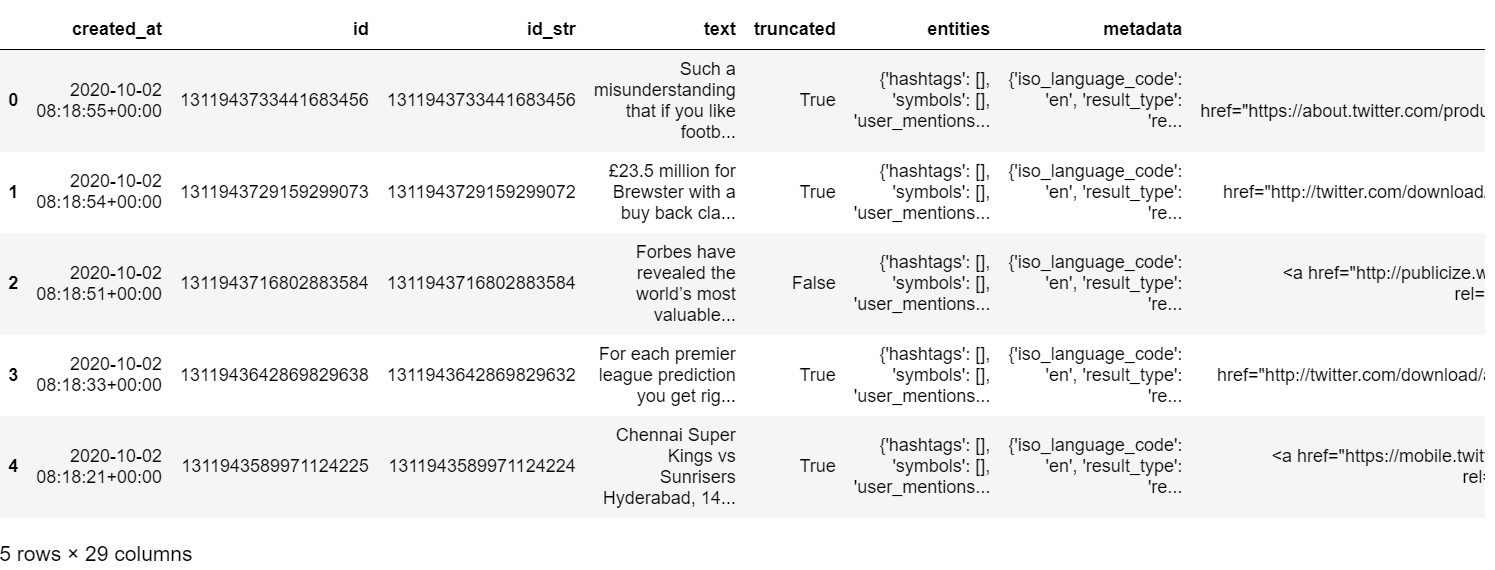
df = pd.read_json('data/tweets-statuses.json')
df[:5]
Tag Named Entities
'''
Iterate through tweets list and
(1) tag the named entities, and
(2) extract and store only entities related to three classes – organization, person, location.
'''
for tweet in df['text']:
# split the tweet by whitespace, into words, and tag them (see o/p lst_tags)
lst_tags = st.tag(tweet.split())
for tup in lst_tags: # for each (tag, word) tuple in lst_tags
if(tup[1] != 'O'): # exclude 'O' (Outside - do not belong to named entity class)
entities.append(tup)
lst_tags # list of tags for the last tweet
[('Liverpool', 'ORGANIZATION'),
('are', 'O'),
('on', 'O'),
('the', 'O'),
('verge', 'O'),
('of', 'O'),
('selling', 'O'),
('Rhian', 'PERSON'),
('Brewster,', 'O'),
('a', 'O'),
('player', 'O'),
('who', 'O'),
('has', 'O'),
('yet', 'O'),
('to', 'O'),
('play', 'O'),
('a', 'O'),
('Premier', 'O'),
('League', 'O'),
('game,', 'O'),
('for', 'O'),
('£23.5…', 'O'),
('https:t.co6yuDSdxbjW', 'O')]
# Print the first 20 entities
entities[:20]
[('Premier', 'ORGANIZATION'),
('League', 'ORGANIZATION'),
('La', 'ORGANIZATION'),
('Liga', 'ORGANIZATION'),
('Brewster', 'PERSON'),
('Swansea', 'LOCATION'),
('Forbes', 'PERSON'),
('Premier', 'ORGANIZATION'),
('League', 'ORGANIZATION'),
('Chennai', 'ORGANIZATION'),
('Super', 'ORGANIZATION'),
('Kings', 'ORGANIZATION'),
('Premier', 'ORGANIZATION'),
('League', 'ORGANIZATION'),
('Europa', 'ORGANIZATION'),
('League', 'ORGANIZATION'),
('Burnley', 'ORGANIZATION'),
('Southampton', 'ORGANIZATION'),
('Everton', 'ORGANIZATION'),
('@MrAncelotti', 'ORGANIZATION')]
Dataframe df_entities
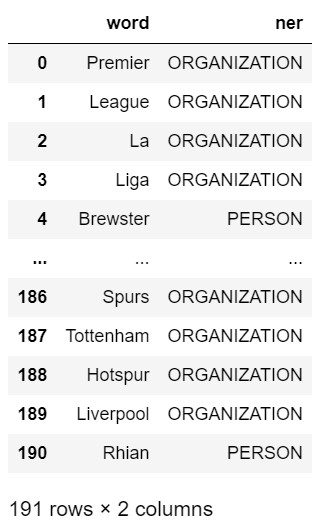
# Load entity tuples to dataframe df_entities and name the columns “word” and “ner”
df_entities = pd.DataFrame(entities)
df_entities.columns = ["word","ner"]
df_entities
Extract Organizations
from collections import Counter
'''
Counter is a class from the collections module that counts the frequency of elements
in a collection, like a list. It returns a dictionary-like object where keys are the
elements, and values are their counts.
'''
# Filter df_entities to extract rows with NER = Organisations.
organizations = df_entities[df_entities['ner'].str.contains("ORGANIZATION")]
# top 10 Organisations: Get the top 10 most mentioned organizations.
cnt = Counter(organizations['word'])
cnt.most_common(10)
[('League', 18),
('Premier', 15),
('Burnley', 6),
('Southampton', 5),
('Liverpool', 5),
('Tottenham', 4),
('United', 3),
('La', 2),
('Europa', 2),
('Sheffield', 2)]
Extract People
# Filter df_entities to extract rows with NER = PERSON.
people = df_entities[df_entities['ner'].str.contains("PERSON")]
# top 10 Persons: Get the top 10 most mentioned persons.
cnt = Counter(people['word'])
cnt.most_common(10)
[('Brewster', 5),
('Harry', 4),
('Kane', 3),
('Saliba', 2),
('Thiago', 2),
('Rhian', 2),
('Jose', 2),
('Mourinho', 2),
('Carlos', 2),
('Vinicius', 2)]
Extract Locations
# Filter df_entities to extract rows with NER = LOCATION.
locations = df_entities[df_entities['ner'].str.contains("LOCATION")]
# top 5 Locations: Get the top 10 most mentioned locations.
cnt = Counter(locations['word'])
cnt.most_common(5)
[('Swansea', 1), ('Accra', 1), ('Liverpool', 1), ('West', 1), ('Ham', 1)]
Liverpool Tweets
# Extract the tweets containing the organization ‘Liverpool’.
liverpool_tweets = df[df['text'].str.contains('Liverpool')]
print(liverpool_tweets['text'])
16 Liverpool have had over 60 million combined fo... 18 Liverpool won the champions league and premier... 21 The extravagance of England's Premier League: ... 44 Really wanted this kid to make it at Liverpool... 69 This is a great deal. He’s never kicked a ball... 92 Liverpool career: Premier League appearances: ... 99 Liverpool are on the verge of selling Rhian Br... Name: text, dtype: object
Exhibit 25.31 Python implementation of Named Entity Recognition (NER) using Stanford NER to identify and classify entities into three categories — organization, person, location. Jupyter notebook.
Previous Next
Use the Search Bar to find content on MarketingMind.





Contact | Privacy Statement | Disclaimer: Opinions and views expressed on www.ashokcharan.com are the author’s personal views, and do not represent the official views of the National University of Singapore (NUS) or the NUS Business School | © Copyright 2013-2026 www.ashokcharan.com. All Rights Reserved.