
-
Marketing mix Modelling
Marketing mix Modelling
Sales Response Function
Linear
Concave
Convex
S-Curve
Interaction Effects
Competitive Effects and Market Share Models
Market Share Models
Dynamic Effects
Adstock
Adfactor
Leads and Lags
Parameter Functions
Long Term Effect (Advertising)
Baseline and Incremental Volume
Promotions Response Model
Model Validity — How Good is the Fit?
Watchouts and Guidelines
Interpretation and Analysis
Discount Elasticity
Cannibalization
Sales Decomposition and Due-To Analysis
What-If Analysis
- Basic Statistics
- Sampling
- Marketing mix Modelling
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
-
MarketingMind
Marketing mix Modelling
Marketing mix Modelling
Sales Response Function
Linear
Concave
Convex
S-Curve
Interaction Effects
Competitive Effects and Market Share Models
Market Share Models
Dynamic Effects
Adstock
Adfactor
Leads and Lags
Parameter Functions
Long Term Effect (Advertising)
Baseline and Incremental Volume
Promotions Response Model
Model Validity — How Good is the Fit?
Watchouts and Guidelines
Interpretation and Analysis
Discount Elasticity
Cannibalization
Sales Decomposition and Due-To Analysis
What-If Analysis
- Basic Statistics
- Sampling
- Marketing mix Modelling
- Marketing Education
- Is Marketing Education Fluffy and Weak?
- How to Choose the Right Marketing Simulator
- Self-Learners: Experiential Learning to Adapt to the New Age of Marketing
- Negotiation Skills Training for Retailers, Marketers, Trade Marketers and Category Managers
- Simulators becoming essential Training Platforms
- What they SHOULD TEACH at Business Schools
- Experiential Learning through Marketing Simulators
Watchouts and Guidelines — Market Response Models
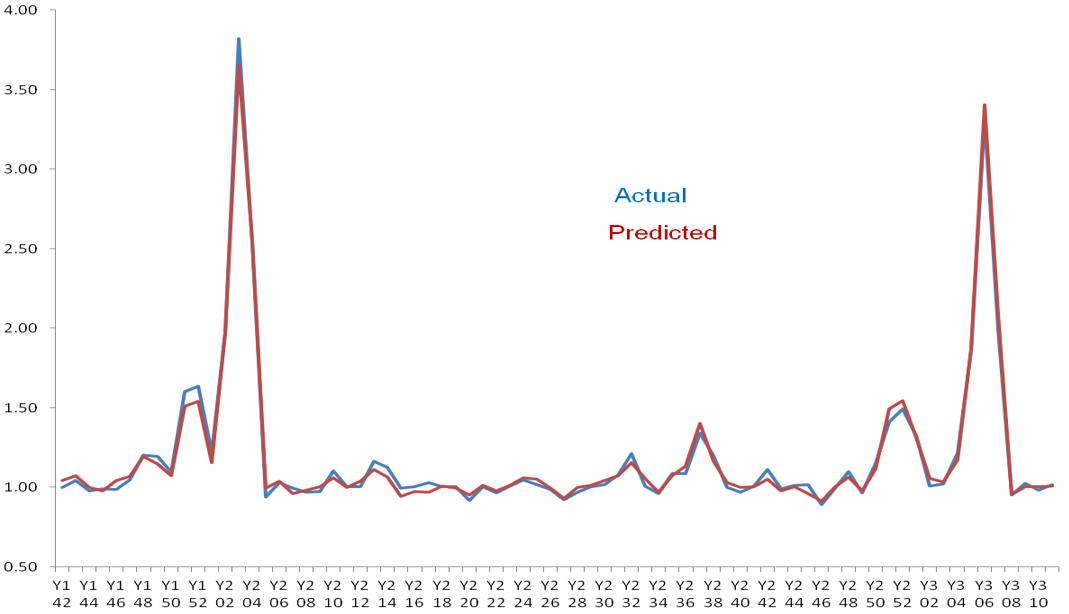
It is important to be cautious when evaluating the quality of market models, as it is easy to construct models that visually appear to have a good fit with the data (e.g., Exhibit 36.9), but are weak, incorrect or nonsensical upon closer analysis. For example, a model may have a high R2 value and appear to closely match predicted and actual data, but fail to accurately capture the underlying relationships between variables or incorporate important variables that affect market behaviour.
Experienced market modelers are aware of these potential issues and are skilled in identifying them. However, if you are not experienced, it can be difficult to assess the quality of a market model. To avoid being deceived by deceptively good-looking models, it is important to be aware of potential issues and pitfalls.
Inclusion of All Sales Drivers
First and foremost, when it comes to developing market models, the knowledge of the market is as important as the knowledge of econometrics. The decision maker who uses the model and the econometrician, who builds it, need to work closely to create a practical solution based on market realities. It is very important that the market dynamics are clearly understood by the developer, that all of the variables that drive performance are included.
All too often in an era of commoditization of market modelling, data is shipped from the marketer to the market modeller, without the necessary information about the characteristics or nuances of the market. For instance, a modeller based overseas may have no knowledge of the Hungry Ghost festival (which is celebrated in countries with significant Chinese populations), the exclusion of which may result in spuriously high elasticities for the brands that are promoted during the festival.
While the exclusion from a model of any factor that significantly influences performance is likely to compromise the validity of the model, measures like R2 will still look good despite the omission. This is because marketing initiatives often occur concurrently, so the impact of the missing variables is attributed to other variables, exaggerating their importance.
In conclusion, it is essential to note that all factors that significantly influence the dependent variable (sales), including external exogenous factors, should be included, regardless of whether or not they are directly related to the research objective.
Potential Difficulties in Estimating Parameters
Modelling works by correlating fluctuations in sales to those in the explanatory factors. If there is no variation in the movement of a particular factor within the data, its potential effect cannot be calculated. For example, if a product has never been offered on discount, it is not possible to calculate its discount elasticity of demand.
Furthermore, when two or more factors consistently occur simultaneously and in similar proportions, it becomes difficult to isolate their individual influences on sales. In such cases, it may be challenging to untangle their effects and determine their respective contributions to sales fluctuations.
Previous Next
Use the Search Bar to find content on MarketingMind.





Contact | Privacy Statement | Disclaimer: Opinions and views expressed on www.ashokcharan.com are the author’s personal views, and do not represent the official views of the National University of Singapore (NUS) or the NUS Business School | © Copyright 2013-2026 www.ashokcharan.com. All Rights Reserved.