Data mining is the process of
scouring and analysing large datasets, and extracting patterns from the data.
Data mining techniques combine methods from statistics and machine learning,
with database management, to predict behaviours and trends. Data mining allows
marketers to take proactive, knowledge-driven decisions. Application areas include:
- Promotions — Identify customers most likely to respond to a
promotional offer.
- Direct marketing — Identify prospects most likely to respond to
direct marketing campaign.
- Interactive marketing — Predict what webpages an individual
accessing a website is most likely to be interested in viewing.
- Market basket analysis — Determine what products or services are
commonly purchased together.
- Churn analysis — Identify customers who are likely to drop a
product or service, and shift to a competitor.
- Fraud detection — Identify which transactions are most likely to
be fraudulent.
Tools used for data mining include neural networks, decision
trees, association rule learning, rule induction, genetic algorithms, nearest neighbour, cluster analysis, classification, and regression. Some of
these tools are described below.
Rule Induction
Rule induction is an area
of machine learning in which formal rules are extracted from a set of
observations. The rules extracted may represent a full scientific model of the
data, or merely represent local patterns in the data.
The rules are usually stated as expressions of the
form:
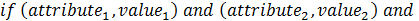
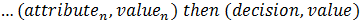
For example:
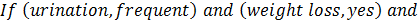
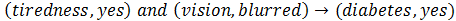
Association Rule Learning
Association rule learning is a method for discovering interesting relationships (association rules based
on the concept of strong rules) among variables in databases. It deploys a
range of algorithms to identify strong rules in databases using different
measures of “interestingness”. For example, shopping basket analysis
of loyalty panel data is used to discover interesting relationships between
products such as 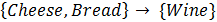
(i.e.
shoppers who buy cheese and bread also tend to buy wine). Information of this
nature may be used for merchandising (e.g., special displays) and promotional
activities.
Association rule learning is also used in a variety
of other applications including web usage mining, intrusion detection,
continuous production, and bioinformatics.
Genetic Algorithms
Genetic algorithms optimization
techniques are based on the concepts of genetic combination, mutation, and
natural selection. Potential solutions are encoded as “chromosomes” that can
combine and mutate. Survival within a modelled “environment” depends on
fitness or performance of each individual chromosome in the population. These
“evolutionary” algorithms are well-suited for solving nonlinear problems.
Examples of applications include speech recognition, robotics, planning and
scheduling, optimizing portfolio investments and so on.
Classification Techniques
Classification techniques
identify the categories where a new observation belongs, based on a set of
variables and a training data set containing observations whose category
membership is known. The classification rules are derived from the training
data set, and the algorithm is referred to as a classifier. Applications
include assigning an email into “spam” or “non-spam”, or predicting customer
behaviour in terms of purchasing, consumption, churn and so on.
Because they use training sets, classification
techniques are described as supervised learning.
Cluster analysis on the other hand, is unsupervised learning.
Nearest Neighbour
Nearest neighbour is
a technique that classifies records in a database based on their similarity.
Cluster Analysis
Cluster analysis is a statistical
technique used to form groups of objects with similar characteristics into
clusters (segments). In cluster analysis the variables used for clustering are
known in advance. Refer to Chapter Segmentation
for details on the application of cluster analysis for market segmentation.





